Rstudio::conf(2022)

RStudio Conference Experience from a First Time Attendee
tl;dr
rstudio:::conf is SO FUN! Workshops are aimed at neurotypical learners and everything is available later so go to the talks of speakers you admire. I will be back and even more prepared to get the most out of everything Posit has to offer.
Workshops - Day 1
Clinical Reporting in R
For the first half of the day, I attended the Clinical Reporting in R workshop from the Data Science team at GSK. I was introduced to TONS of acronyms of many new-to-me concepts within clinical trials reporting (i.e., CDISC, ADAM, ARD). Unfortunately, the workshop was aimed at walking through documentation of a single new package from GSK (tfrmt) and lacked the continuity I was wanting from the overall RStudio community experience. tfrmt is a very cool package that greatly increases the reproducibility of reformatting trial results for numerous submissions. However, because of the goal of helping newer R users to implement the tfrmt package instead of helping newer data scientists familiarize themselves with clinical reporting, I found myself looking for a new workshop by lunch.
Machine Learning with Tidymodels
I already knew I loved tidymodels, because I love the tidyverse and everything Julia Silge. However, when I scripted my warfarin machine learning paper, I recall feeling like I was working on an alpha that wasn’t completely ready so I jumped into a very full Machine Learning with Tidymodels classroom with Max Kuhn.
This workshop was a nice mix between concepts of machine learning and how to use tidymodels to implement tidy, reproducible modeling methods in R. I found myself completely baffled by vetiver and the concept of versioning, deploying, and monitoring a model. One of the major issues I ran into when trying to reproduce the results from the most popular warfarin dosing algorithm in my field was trying to use their model to predict dose in my cohort within my code. Their model was deployed on a website that would have forced me to predict dose patient by patient after manually including metadata. In my understanding, if this popular paper had employed a tool like vetiver to deploy their model, other researchers such as myself would have an easier time gathering the information from that model. Additionally, vetiver would allow the maintainers of the original model to continuously include more data and re-deploy the model instead of archiving in a publication.
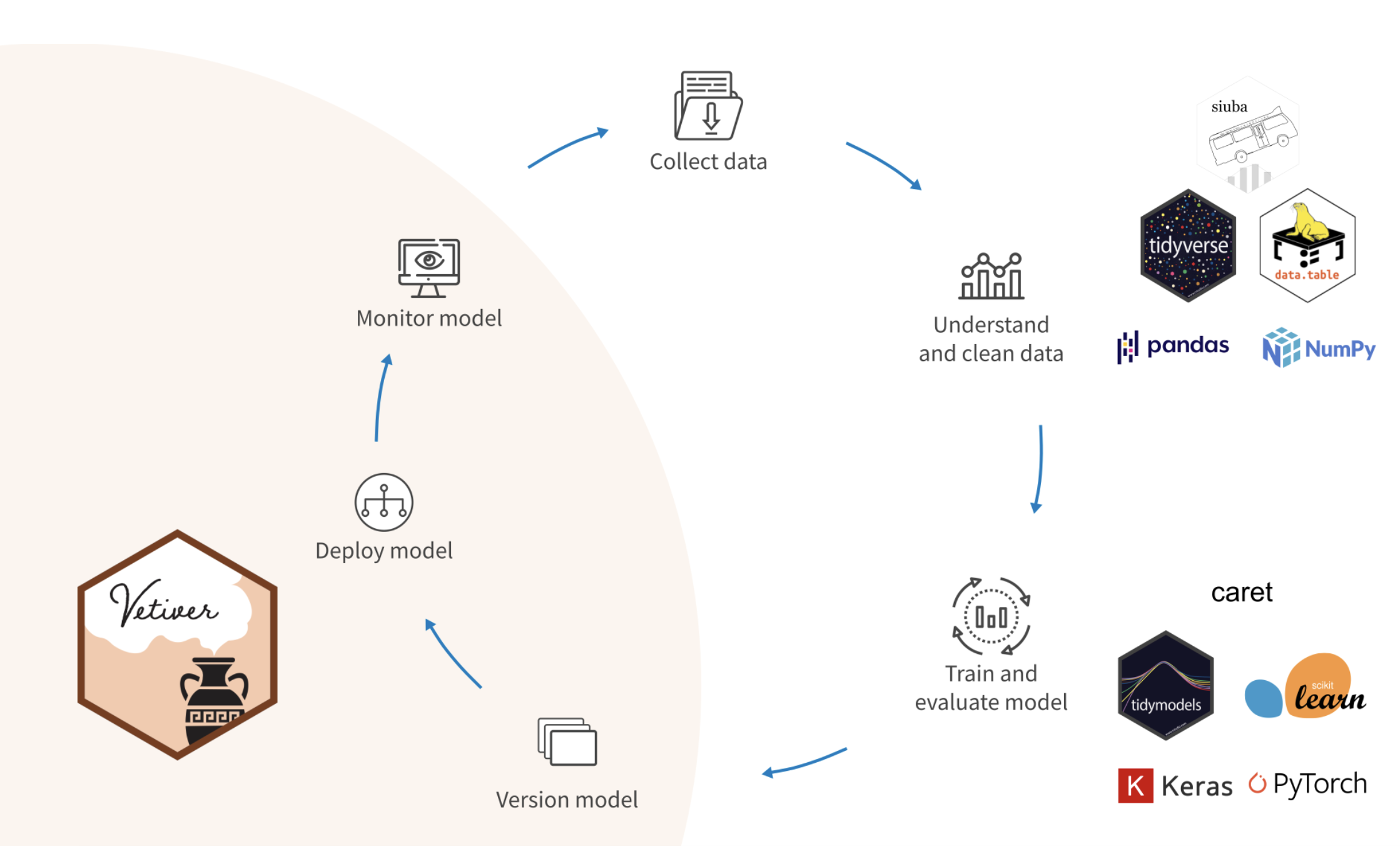
My warfarin machine learning paper didn’t even deploy a model! Think about all the new information I could be gaining from having others test my model with their data! The information loss! The horror!
Workshops - Day 2
more Machine Learning with Tidymodels
On day two of tidymodels, I gained a lot more comfort around my greatest fear, “who’s going to stop me from messing this all up?". The truth is that if you follow the steps provided and test a bunch of models in the meantime, you’ll know if you’ve made some horrible error.
The logistic model beat xgboost so that’s how I know ML is fake. /s
Conference - Day 1
Day 1 of the conference I got another dose of the industry data science experience, from PowerBI integration with R to another version of tfrmt (tplyr) from another company to Azure -> RStudio Connect! Unfortunately, I was putting a lot of faith into slides being available from all presenters so I focused on listening over note-taking. Now I have few notes. I promise to write-up my thoughts (here or another post) after recordings are posted.
WTF-AITA, What They Forgot to teach you About Industry Transitions from Academia, from the What They Forgot series was hilarious and much needed. I have already created a GitHub README and cleaned up my repositories with the intention of folks looking at my work.
I finally met some healthcare folks to chat with! I asked a lot of questions and got a lot of blank stares! 😂 However, squeezing a tiny amount of information out of the non-disclosure sealed mouths was just enough to help me get to the google searches of my dreams. I have been looking for open health data science tools for >5 years and keywords such as healthyverse and pharmaverse led me to https://openpharma.github.io/!
Conference - Day 2
Day 2 was filled with tips and tricks about working with teams and across tools and featured two really killer keynotes from Mine Çitenkaya-Rundel and Julia Stewart Lowndes in the morning, and Jeff Leek to close out the conference. Regardless of the fact that I taught a whole workshop about Quarto in May, I audibly gasped when shown how to use to visual editor like a pro. Also, wouldn’t a DataTrail program in Tucson called “The Loop” be adorable?
This talk, How to be a PollinatoR, was probably my favorite that I attended. Another fun talk, for me, was from the National Institutes of Health - I did not expect to see them at conf! The thought of the NIH doing machine learning on my proposals made me giggle.
In Conclusion
That was so fun. It was a LONG conference and Posit is a little culty, but I had an amazing experience. I think in the future, I’d not participate in the workshop days so that I could make optimal use of brain power for the conference talks. Breakfast socials that started at 4AM local time weren’t super realistic, for me. Lunch and evening social events were awesome, though! In the future, I can make better use of the conference schedule prior to the event because I have a better understanding of the tagging system.
I have at least 100 hex stickers if you’re interested DM me on slack!
Heidi E. Steiner
Senior Clinical Data Scientist
I love coding in R, biostatistics, and reproducible clinical research.