Machine Learning for Prediction of Stable Warfarin Dose in US Latinos and Latin Americans
Abstract
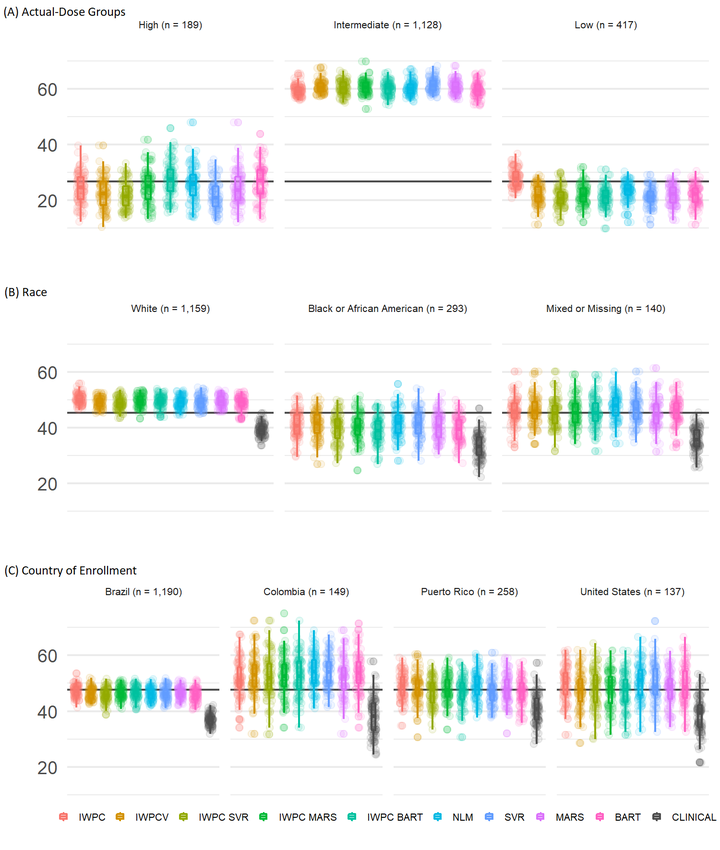
Populations used to create warfarin dose prediction algorithms largely lacked participants reporting Hispanic or Latino ethnicity. While previous research suggests nonlinear modeling improves warfarin dose prediction, this research has mainly focused on populations with primarily European ancestry. We compare the accuracy of stable warfarin dose prediction using linear and nonlinear machine learning models in a large cohort enriched for US Latinos and Latin Americans (ULLA). Each model was tested using the same variables as published by the International Warfarin Pharmacogenetics Consortium (IWPC) and using an expanded set of variables including ethnicity and warfarin indication. We utilized a multiple linear regression model and three nonlinear regression models - Bayesian Additive Regression Trees, Multivariate Adaptive Regression Splines, and Support Vector Regression. We compared each model’s ability to predict stable warfarin dose within 20% of actual stable dose, confirming trained models in a 30% testing dataset with 100 rounds of resampling. In all patients (n=7,030), inclusion of additional predictor variables led to a small but significant improvement in prediction of dose relative to the IWPC algorithm (47.8% versus 46.7% in IWPC, p=1.43x10-15). Nonlinear models using IWPC variables did not significantly improve prediction of dose over the linear IWPC algorithm. In ULLA patients alone (n=1,734), IWPC performed similarly to all other linear and nonlinear pharmacogenetic algorithms. Our results reinforce the validity of IWPC in a large, ethnically diverse population and suggest that additional variables that capture warfarin dose variability may improve warfarin dose prediction algorithms.
Heidi E. Steiner
Senior Clinical Data Scientist
I love coding in R, biostatistics, and reproducible clinical research.